字符集和编码
2023-03-30
3 min read
ASCII
- 一个字节8位,可以表示256个状态
- 第一位是0,0~127,数字、大小写英文字母、标点符号、空格、控制符等
- 扩展128~255,Latin-1字符集
汉字编码
- GB2312
- 两个大于127的字节组合编码,一共收录了7445个字符,包括6763个汉字和682个其它符号。
- 全角符号(数字、英文字母、标点符号)
- 生僻字存不下。Google搜索: 朱(容加金旁)基

- GBK
- 只要第一个字节大于127表示是汉字,需要读取两个字节组合。收录了21886个符号,包括21003个汉字和883个其它符号。
- Google搜索: 生僻字 身份证
- 生僻姓名的人,在实名制系统之外的那些日子
- GB18030
- 增加少数民族文字、CJK统一汉字等
- 采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符。
- 一个名字带“䶮”的人开不了银行账户 探询金融系统生僻字输入解决方案
- GB13000
- 基本等同于UTF16编码
- 台湾的繁体字BIG5也采用了类似的编码,导致编码不互通
Unicode
- Unicode,全世界所有字符统一编码
- Unicode 将编码空间分成 17 个平面,以 0 到 16 编号,每平面拥有65536(即2^16)个代码点,
- 第 0 平面(或者说基本多文种平面BMP)中的码点,都可以用一个 UTF-16 单位来编码,或者以 UTF-8 来编码的话,会使用一、二或三个字节。而第 1 到 16 平面(或称辅助平面)中的码点,UTF-16 会以代理对的方式来使用,而 UTF-8 则会编码成 4 个字节。
- Unicode 字符百科
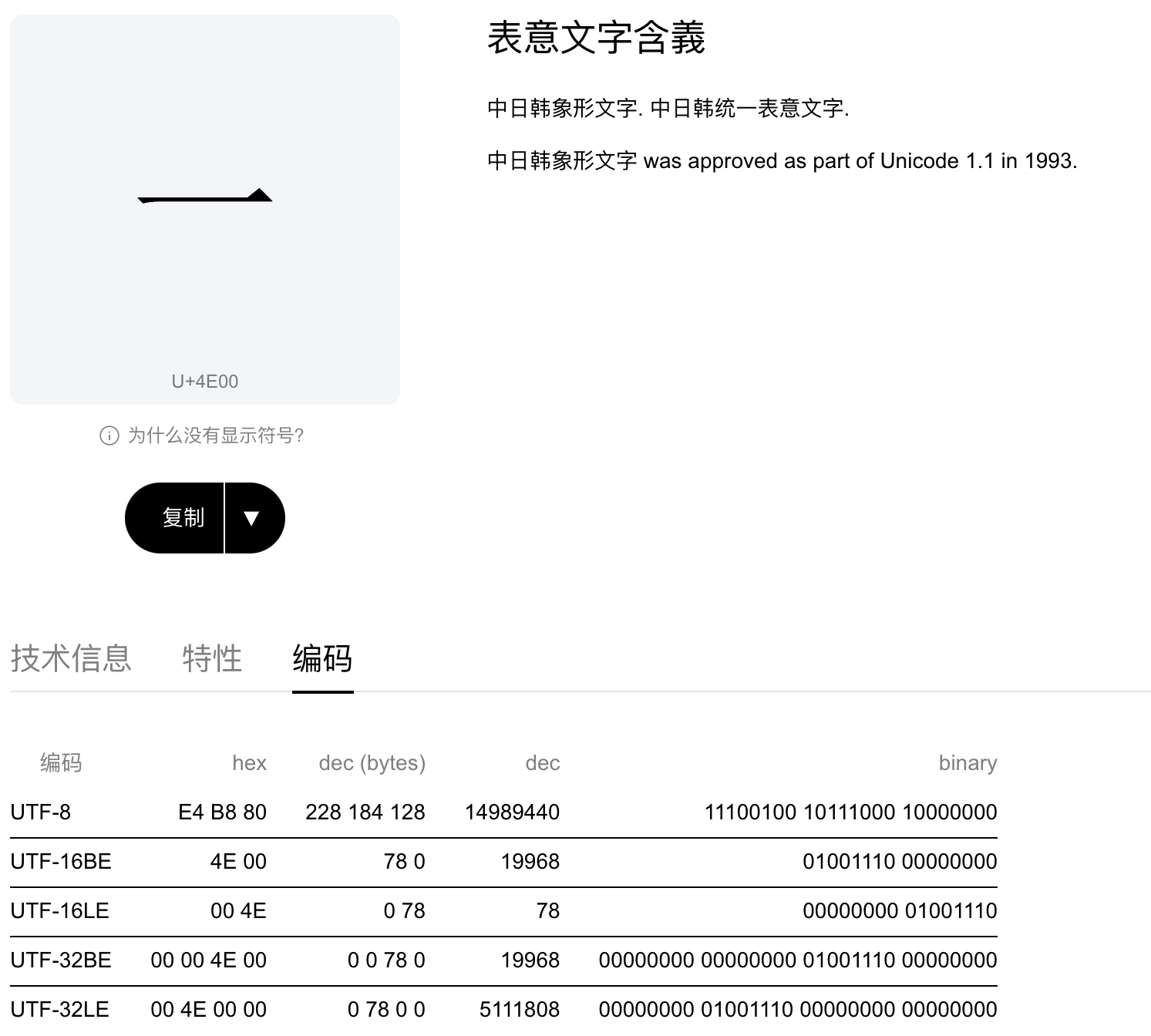
- 汉字:
- BMP中,包含了27,973个汉字(中日韩表意文字+扩展A)
- 辅助平面,中日韩表意文字扩展区B、C、D、E、F、G、H
- 中日韩表意文字 截止2022年总计97058个
- 特殊区域
- 易混淆,unicode hack


UTF(Unicode Transformation Format)
-
UTF8,变长编码,1~4个字节
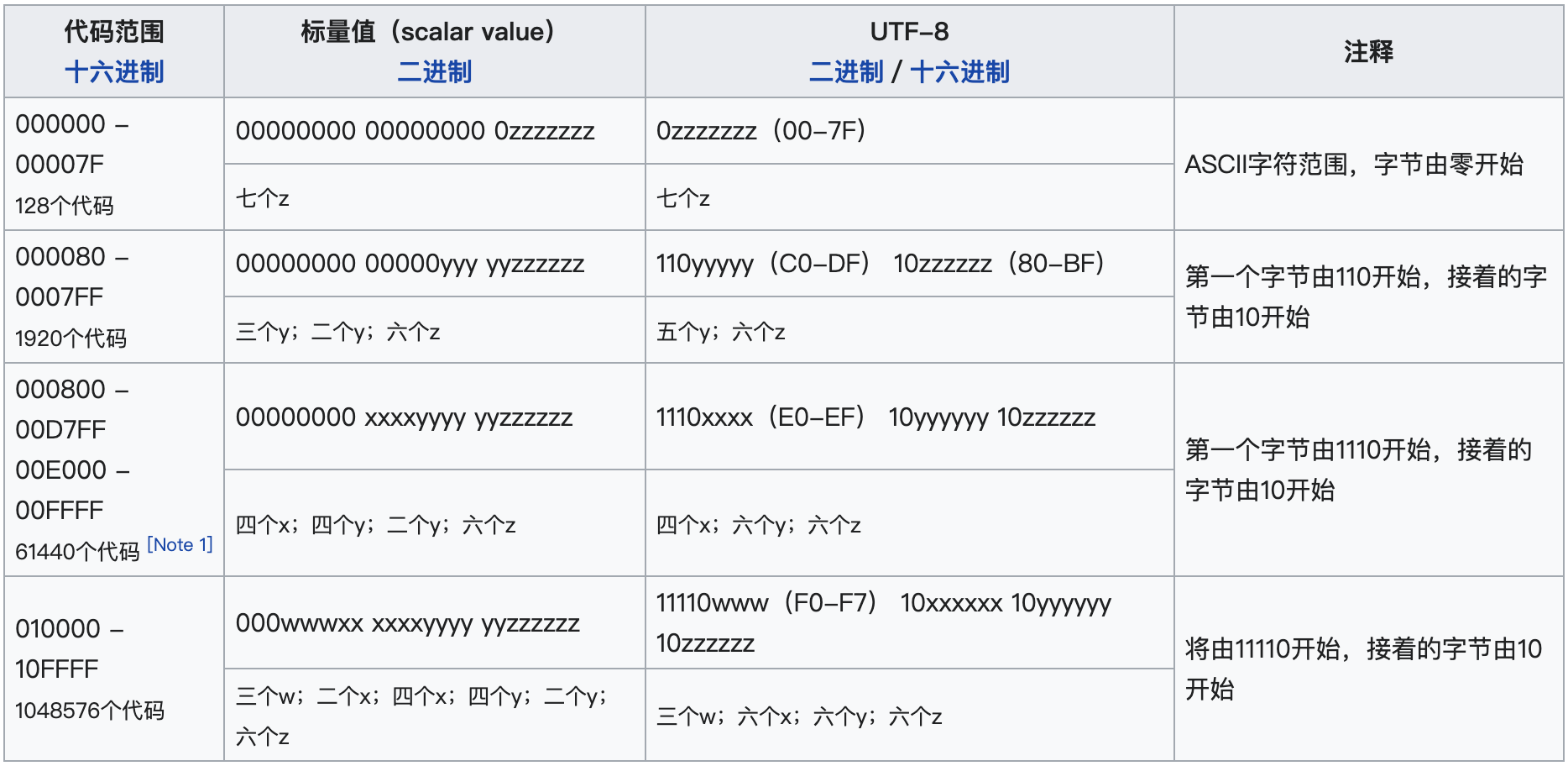
- 1字节:ASCII
- 2字节:11位编码空间,拉丁字母、希腊字母等1920个字符
- 3字节:16位编码空间,BMP所有剩余字符(2万多常用汉字)
- 4字节:21位编码空间,辅助平面1~16(生僻字古汉字,扩展中日韩象形文字)
-

- 2字节:和Unicode编码一致,所有BMP平面(2万多常用汉字)
- 4字节:代理对,辅助平面(生僻字古汉字,扩展中日韩象形文字)
- Java中char采用UTF16编码,两字节
- UTF16LE、UTF16BE
示例
- BMP
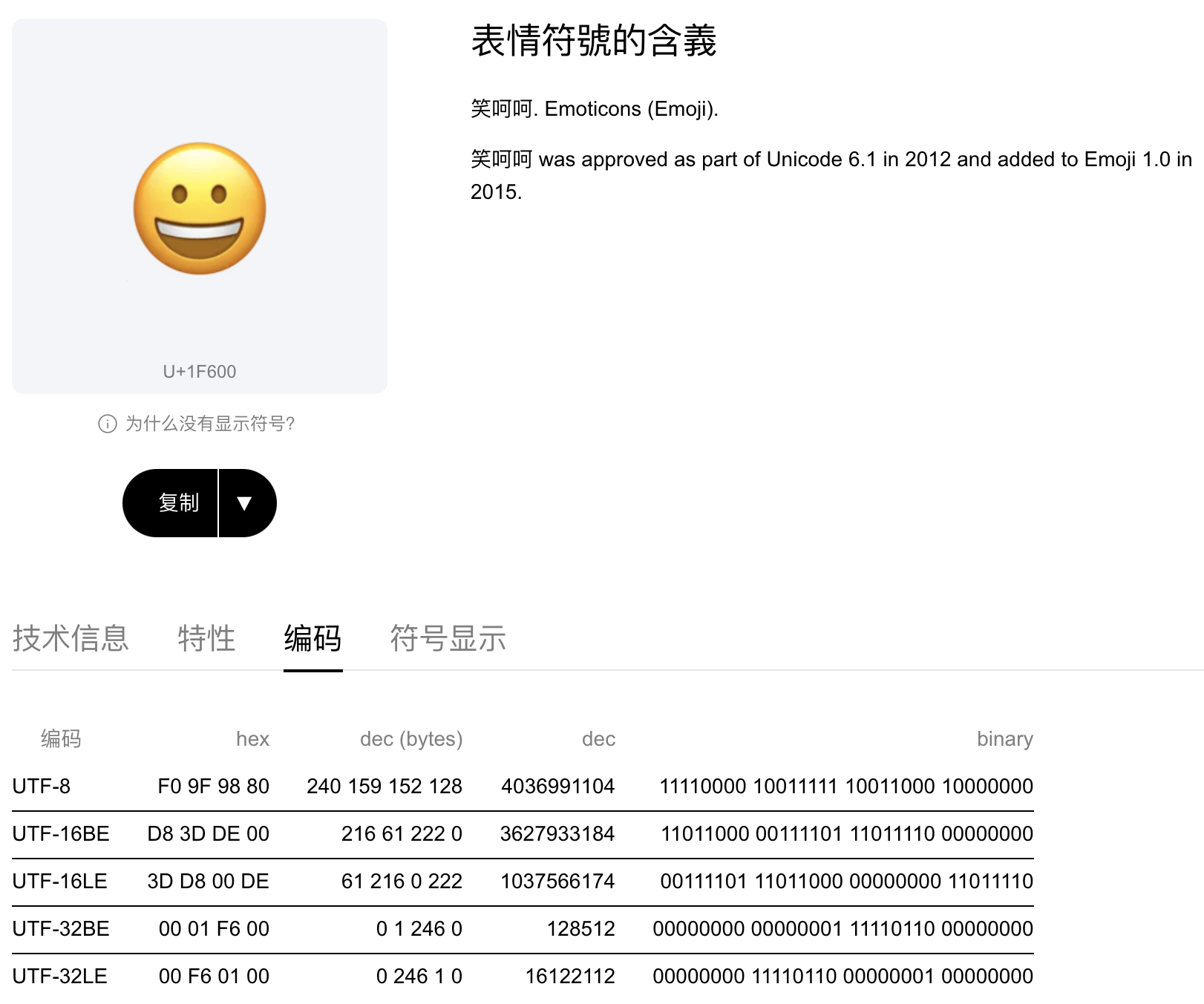
- 辅助平面
- 在Unicode标准中,Emoji符号被视为一种特殊字符,主要被分配在U+1F300到U+1F6FF的范围
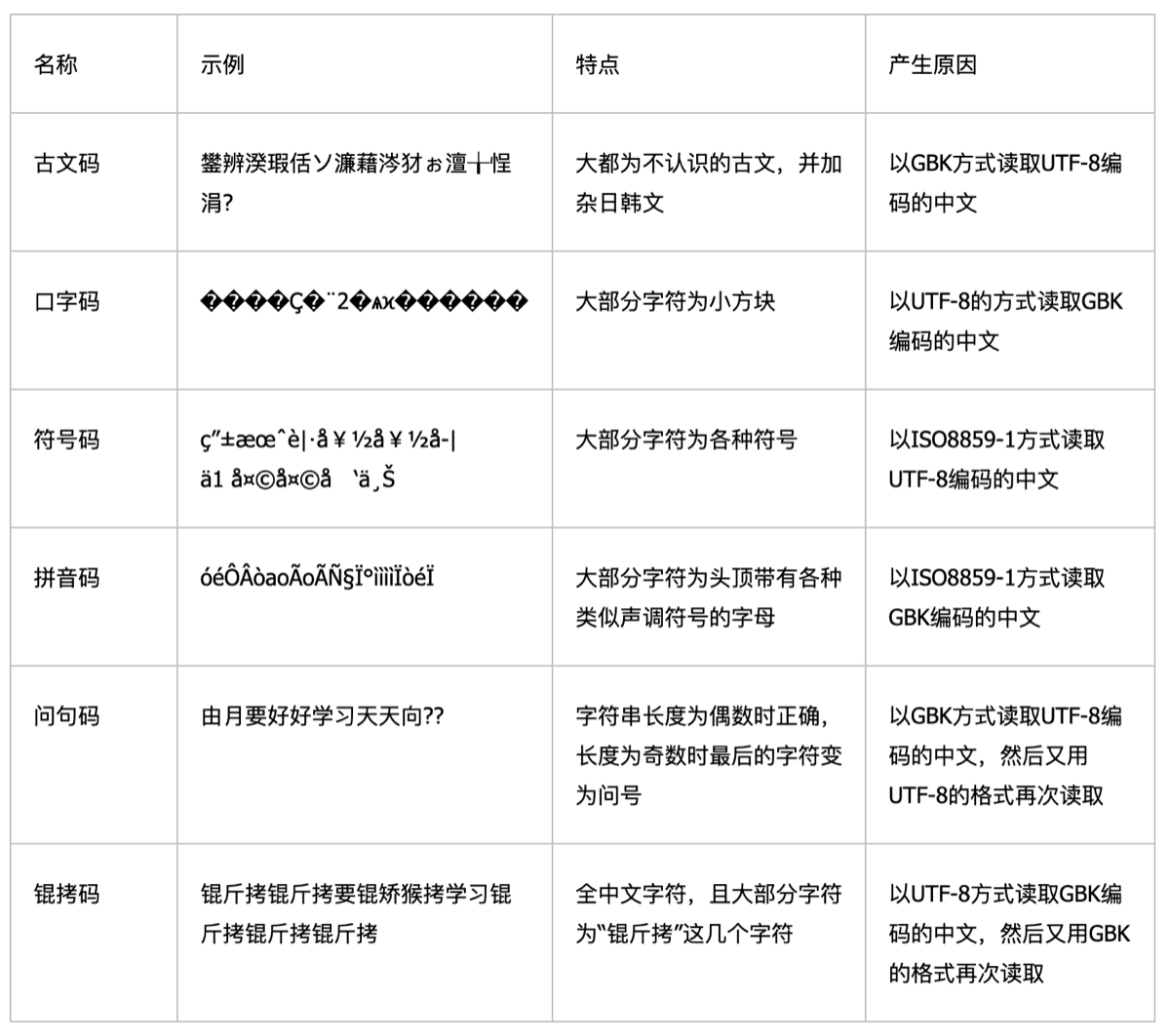
- 常见乱码
- 手持两把锟斤拷,口中疾呼烫烫烫